6. 对比 loguru 10胜
nb_log对比 loguru,必须对比,如果比不过loguru就不需要弄nb_log浪费精力时间
6.1 先比控制台屏幕流日志颜色,nb_log三胜。
这是loguru 屏幕渲染颜色
1)nb_log 颜色更炫
2)nb_log 自动使用猴子补丁全局改变任意print
3)nb_log 支持控制台点击日志文件行号自动打开并跳转到精确的文件和行号。
6.2 比文件日志性能,nb_log比loguru快400%。
nb_log为了保证多进程下按大小安全切割,采用了文件锁 + 自动每隔1秒批量把消息写入到文件,大幅减少了加锁解锁和判断时候需要切割的次数。
nb_log的file_handler是史上最强的,超过了任何即使不切割文件的内置filehandler,比那些为了维护自动切割的filehandler例如logging内置的
RotatingFileHandler和TimedRotatingFileHandler的更快。比为了保证多进程下的文件日志切割安全的filehandler更是快多了。
比如以下star最多的,为了确保多进程下切割日志文件的filehandler
https://github.com/wandaoe/concurrent_log
https://github.com/unlessbamboo/ConcurrentTimeRotatingFileHandler
https://github.com/Preston-Landers/concurrent-log-handler
nb_log的多进程文件日志不仅是解决了文件切割不出错,而且写入性能远超这些4到100倍。
100倍的情况是 win10 + https://github.com/Preston-Landers/concurrent-log-handler对比nb_log
nb_log的文件日志写入性能是loguru的4倍,但loguru在多进程运行下切割出错。
6.2.1 loguru快速文件写入性能,写入200万条代码
这个代码如果rotation设置10000 Kb就切割,那么达到切割会疯狂报错,为了不报错测试性能只能设置为1000000 KB
import time
from loguru import logger
from concurrent.futures import ProcessPoolExecutor
logger.remove(handler_id=None)
logger.add("./log_files/loguru-test1.log", enqueue=True, rotation="10000 KB")
def f():
for i in range(200000):
logger.debug("测试多进程日志切割")
logger.info("测试多进程日志切割")
logger.warning("测试多进程日志切割")
logger.error("测试多进程日志切割")
logger.critical("测试多进程日志切割")
pool = ProcessPoolExecutor(10)
if __name__ == '__main__':
"""
100万条需要115秒
15:12:23
15:14:18
200万条需要186秒
"""
print(time.strftime("%H:%M:%S"))
for _ in range(10):
pool.submit(f)
pool.shutdown()
print(time.strftime("%H:%M:%S"))
6.2.2 nb_log快速文件写入性能,写入200万条代码
from nb_log import get_logger
from concurrent.futures import ProcessPoolExecutor
logger = get_logger('test_nb_log_conccreent', is_add_stream_handler=False, log_filename='test_nb_log_conccreent.log')
def f(x):
for i in range(200000):
logger.warning(f'{x} {i}')
if __name__ == '__main__':
# 200万条 45秒
pool = ProcessPoolExecutor(10)
print('开始')
for i in range(10):
pool.submit(f, i)
pool.shutdown()
print('结束')
6.3 多进程下的文件日志切割,nb_log不出错,loguru出错导致丢失大量日志。
将10.2的代码运行就可以发现,loguru设置了10M大小切割,疯狂报错,因为日志在达到指定大小后切割需要备份重命名,
造成其他的进程出错。
win10 + python3.6 + loguru 0.5.3(任何loguru版本都报错,已设置enqueue=True)
出错如下。
Traceback (most recent call last):
File "F:\minicondadir\Miniconda2\envs\py36\lib\site-packages\loguru\_handler.py", line 287, in _queued_writer
self._sink.write(message)
File "F:\minicondadir\Miniconda2\envs\py36\lib\site-packages\loguru\_file_sink.py", line 174, in write
self._terminate_file(is_rotating=True)
File "F:\minicondadir\Miniconda2\envs\py36\lib\site-packages\loguru\_file_sink.py", line 205, in _terminate_file
os.rename(old_path, renamed_path)
PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'F:\\coding2\\nb_log\\tests\\log_files\\loguru-test1.log' -> 'F:\\coding2\\nb_log\\tests\\log_files\\loguru-test1.2021-08-25_15-12-23_434270.log'
--- End of logging error ---
python性能要发挥好,必须开多进程。
例如django flask的部署用gunicorn uwsgi都是自动开多进程+线程(协程),即使你的代码里面没亲自写多进程运行,但是自动被迫用了多进程。
即使你代码没亲自写多进程,例如在同一个机器反复把xx.py启动部署10次,相当于10个进程的日志都写到 yyyy.log,一样是被迫相当于10个进程了。
所以多进程文件日志切割安全很重要。
有的人说自己多进程写文件日志没出错,那是你没设置成按大小或者时间切割,或者自己设置了1G大小切割或者按天切割,不容易观察到。
只要你把时间设置成每1分钟切割或者10M切割,就会很快很容易观察到了。
如果文件日志不进行切割,多进程写同一个文件不会出错的。
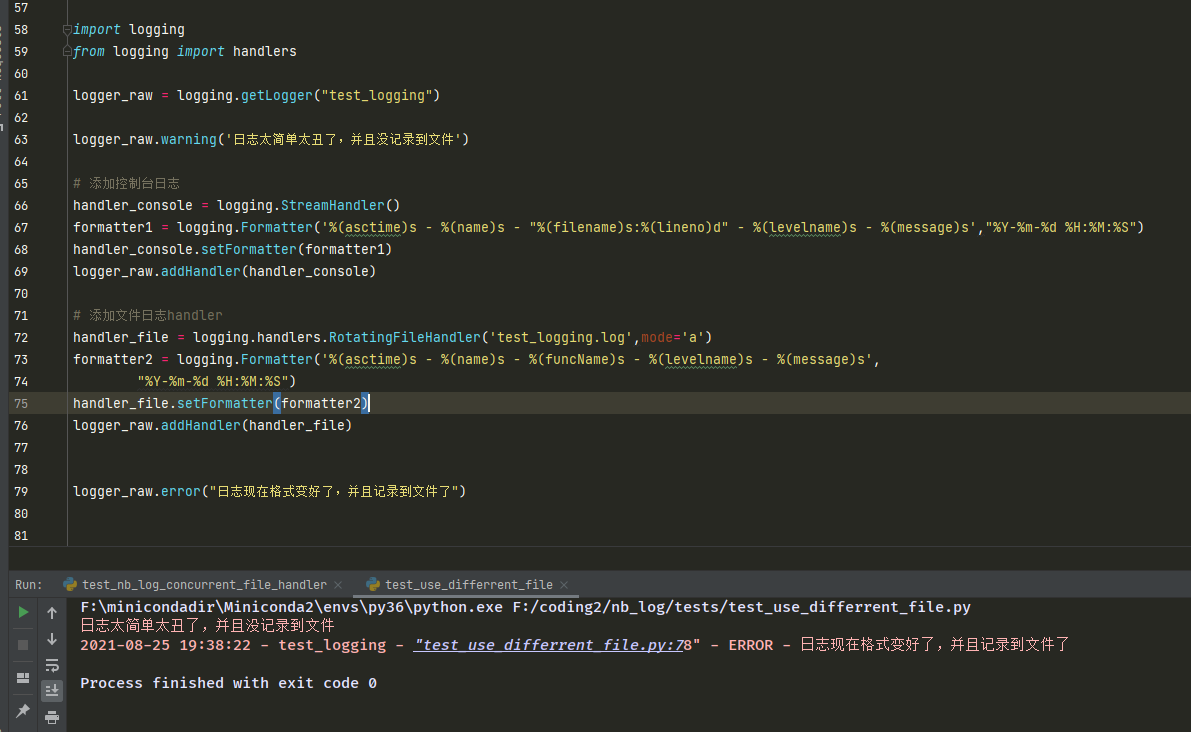
6.4 写入不同的文件,nb_log采用经典日志的命名空间区分日志,比loguru更简单
from nb_log import get_logger
from loguru import logger
# nb_log 写入不同的文件是根据日志命名空间 name 来区分的。方便。
logger_a = get_logger('a', log_filename='a.log', log_path='./log_files')
logger_b = get_logger('b', log_filename='b.log', log_path='./log_files')
logger_a.info("嘻嘻a")
logger_b.info("嘻嘻b")
# loguru 不同功能为了写入不同的文件,需要设置消息前缀标志。不方便。
logger.add('./log_files/c.log', filter=lambda x: '[特殊标志c!]' in x['message'])
logger.add('./log_files/d.log', filter=lambda x: '[特殊标志d!]' in x['message'])
logger.add('./log_files/e.log', )
logger.info('[特殊标志c!] 嘻嘻c') # 出现在c.log和 e.log 消息为了写入不同文件需要带消息标志
logger.info('[特殊标志d!] 嘻嘻d') # 出现在d.log和 e.log 消息为了写入不同文件需要带消息标志
6.5 按不同功模块能作用的日志设置不同的日志级别。loguru无法做到。
例如a模块的功能希望控制台日志可以显示debug,b模块的功能只显示info以上级别。
import logging
from nb_log import get_logger
# nb_log 写入不同的文件是根据日志命名空间 name 来区分的。方便。
logger_a = get_logger('a', log_level_int=logging.DEBUG)
logger_b = get_logger('b', log_level_int=logging.INFO)
logger_a.debug("嘻嘻a debug会显示")
logger_a.info("嘻嘻a info会显示")
logger_b.debug("嘻嘻b debug不会显示")
logger_b.info("嘻嘻b info会显示")
6.6 nb_log内置自带的log handler种类远超loguru
nb_log 内置的handler包括 钉钉 elastic kafka,方便自动一键把日志同时记载到这些地方。
loguru没有内置,loguru的add方法以文件日志为核心。
6.7 比第三方的日志handler扩展数量,nb_log完胜loguru
日志能记载到什么地方是由handler决定的,很多人以为日志等于控制台 + 文件,并不是这样的。
日志可以记载到任何介质,不是只有控制台和文件。
nb_log的核心方法是get_logger,此方法是返回原生loggin.Logger类型的对象,
原生日志可扩展的第三方handler包在pypi官网高达几百个,可以直接被nb_log使用。
6.8 nb_log的get_logger返回类型是原生经典logging.Logger,兼容性达到了100%。loguru独立实现日志系统,兼容性很差。
绝大部分python代码采用的是内置经典的python logging模块,
例如老代码
logger = logging.getLogger("my_namespage")
老代码的其他地方使用了logger对象的这些方法,远不止这两个。
logger.setLevel()
logger.addHandler()
如果是改成nb_log, logger = nb_log.get_logger("my_namespage")
那么logger.setLevel() logger.addHandler() 仍然可以正常使用。
如果是改成loguru, from loguru import logger
那么logger.setLevel() logger.addHandler() 会是代码报错,因为loguru的logger对象是独立特行独自实现的类型,没有这些方法。
6.9 易用性对比,nb_log的控制台和文件handler比loguru添加更容易
loguru哪里好了?
loguru只是自动有好看的日志formatter显示格式 + 比原生logger更容易添加文件handler。
loguru比原生logging也只是好在这两点而已,其他方面这不如原生。
nb_log 比loguru添加控制台和文件日志更简单,并且显示格式更炫。loguru对比原生logging的两个优势在nb_log面前没有了。
原生日志设置添加控制台和文件日志并设置日志格式是比loguru麻烦点,但这个麻烦的过程被nb_log封装了。
6.10 nb_log可以灵活捕获所有第三方python包、库、框架的日志,loguru不行
不知道大家喜欢看三方包的源码不,或者跳转进去看过三方包源码不,
95%的第三方包的源码的大量文件中都有写 logger = logging.getLogger(__name__) 这段代码。
假设第三包的包名是 packagex, 这个包下面有 ./dira/dirb/yy.py 文件,
假设logger = logging.getLogger(__name__) 这段代码在 ./dira/dirb/moduley.py文件中,
当使用这个三方包时候,就会有一个 packagex.dira.dirb.yy.moduley 的命名空间的日志,如果你很在意这个模块的日志,
希望吧这个模块的日志捕获出来,那么可以 logger = logging.getLogger("packagex.dira.dirb.moduley"),
然后对logger添加文件和控制台等各种handler,设置合适的日志级别,就可以显示出来这个模块的日志了。
为什么第三方包不默认给他们自己的logger添加handler呢,这是因为第三方包不知道你喜欢吧日志记载到哪里,而且第三包不知道你会很关心这个模块的日志,
如果每隔第三方包都那么自私,把日志默认添加handler,并且设置成info或debug级别,那各种模块的日志加起来就会很多,干扰用户。很多用户又不知道如何移除handler,
所以三方包都不会主动添加handler,需要用户自己去添加handler和设置用户喜爱的formattor。
代码例子如下,因为requests调用了urllib3,这里有urllib3的命名空间的日志,只是没有添加日志handler所以没显示出来。
nb_log.get_logger 自动加上handler和设置日志模板了,方便你调试你所关心的模块的日志。
from nb_log import get_logger
import requests
get_logger('urllib3') # 也可以更精确只捕获 urllib3.connectionpool 的日志,不要urllib3包其他模块文件的日志
requests.get("http://www.baidu.com")

6.10.b 日志的命名空间意义很重要 ,就是那个logging.getLogger的入参,很多人还不懂。
如果日志名字是 a.b.c
那么 logging.getLogger("a")可以捕获a文件夹下的所有子文件夹下的所有模块下的日志,
logging.getLogger("a.b")可以捕获a/b文件夹下的所有模块下的日志
logging.getLogger("a.b.c") 可以精确只捕获a/b/c.py 这个模块的日志
