2 nb_log的文件日志handler
2.1 nb_log 支持5中文件日志切割方式
这个文件日志的自定义多进程安全按大小切割,filehandler是python史上性能最强大的支持多进程下日志文件按大小自动切割。
关于按大小切割的性能可以看第10章的和loggeru的性能对比,nb_log文件日志写入性能快400%。
nb_log 支持5种文件日志,get_logger 的log_file_handler_type可以优先设置是按照 大小/时间/watchfilehandler/单文件永不切割.
也可以在你代码项目根目录下的 nb_log_config.py 配置文件的 LOG_FILE_HANDLER_TYPE 设置默认的filehandler类型。
nb_log_config.py 的 LOG_PATH 配置默认的日志文件夹位置,如果get_logger函数没有传log_path入参,就默认使用这里的LOG_PATH
在各种filehandler实现难度上
单进程永不切割 < 单进程按大小切割 < 多进程按时间切割 < 多进程按大小切割
因为每天日志大小很难确定,如果每天所有日志文件以及备份加起来超过40g了,硬盘就会满挂了,所以nb_log的文件日志filehandler默认采用的是按大小切割,不使用按时间切割。
文件日志自动使用的默认是多进程安全切割的自定义filehandler,
logging包的RotatingFileHandler多进程运行代码时候,如果要实现向文件写入到规定大小时候并自动备份切割,win和linux都100%报错。
支持多进程安全切片的知名的handler有ConcurrentRotatingFileHandler,
此handler能够确保win和linux切割正确不出错,此包在linux使用的是高效的fcntl文件锁,
在win上性能惨不忍睹,这个包在win的性能在三方包的英文说明注释中,作者已经提到了。
nb_log是基于自动批量聚合,从而减少写入次数(但文件日志的追加最多会有1秒的延迟),从而大幅度减少反复给文件加锁解锁,
使快速大量写入文件日志的性能大幅提高,在保证多进程安全且排列的前提下,对比这个ConcurrentRotatingFileHandler
使win的日志文件写入速度提高100倍,在linux上写入速度提高10倍。
2.2 演示nb_log文件日志,并且直接演示最高实现难度的多进程安全切片文件日志
from multiprocessing import Process
from nb_log import LogManager, get_logger
# 指定log_filename不为None 就自动写入文件了,并且默认使用的是多进程安全的切割方式的filehandler。
# 默认都添加了控制台日志,如果不想要控制台日志,设置is_add_stream_handler=False
# 为了保持方法入场数量少,具体的切割大小和备份文件个数有默认值,
# 如果需要修改切割大小和文件数量,在当前python项目根目录自动生成的nb_log_config.py文件中指定。
# logger = LogManager('ha').get_logger_and_add_handlers(is_add_stream_handler=True,
# log_filename='ha.log')
# get_logger这个和上面一句一样。但LogManager不只有get_logger_and_add_handlers一个公有方法。
logger = get_logger(is_add_stream_handler=True, log_filename='ha.log')
def f():
for i in range(1000000000):
logger.debug('测试文件写入性能,在满足 1.多进程运行 2.按大小自动切割备份 3切割备份瞬间不出错'
'这3个条件的前提下,验证这是不是python史上文件写入速度遥遥领先 性能最强的python logging handler')
if __name__ == '__main__':
[Process(target=f).start() for _ in range(10)]
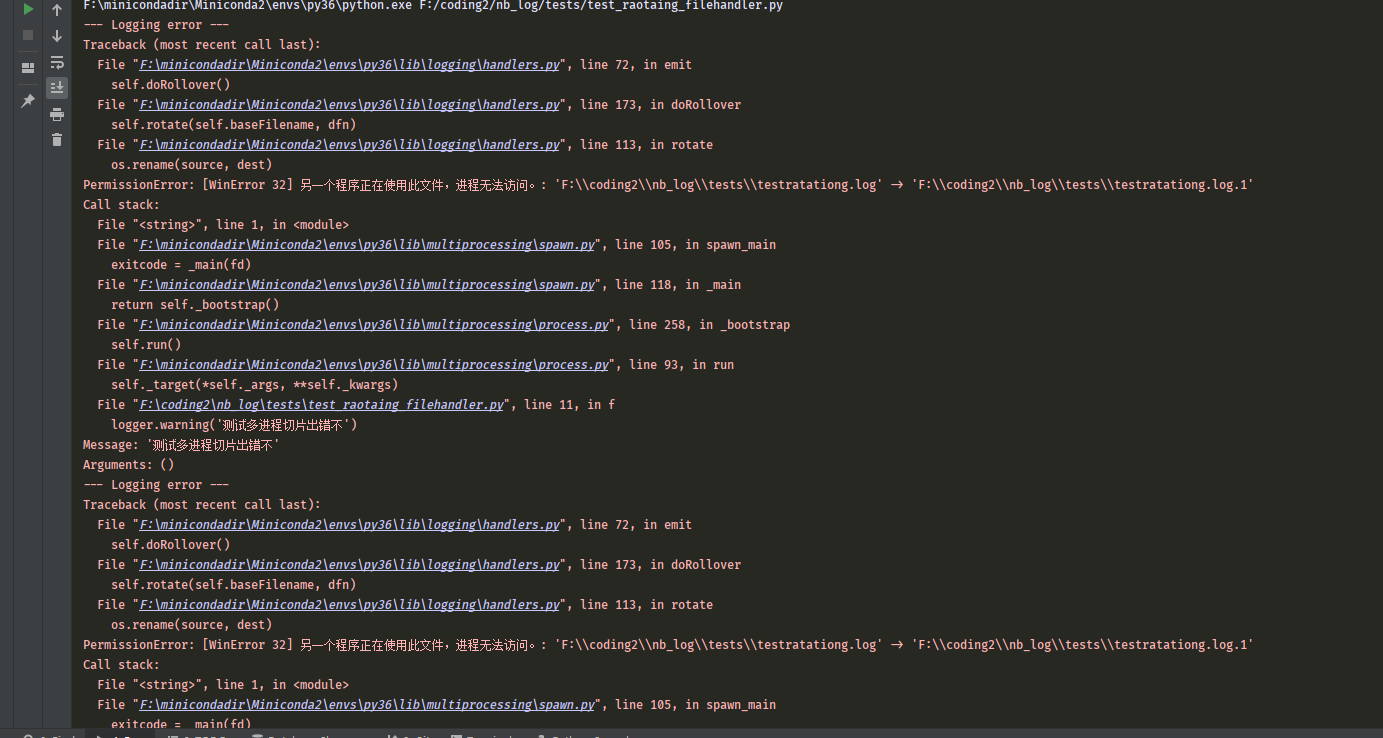
2.3 演示文件大小切割在多进程下的错误例子,
注意说的是多进程,任何handlers在多线程下都没有问题,任何handlers在记录时候都加了线程锁了,完全不用考虑多线程。
线程锁不能跨进程特别是跨不同批次启动的脚本运行的解释器。
所以说的是多进程,不是多线程。
下面这段代码会疯狂报错。因为每达到100kb就想切割,多个文件句柄引用了同一个文件,某个进程想备份改文件名,别的进程不知情。
解决这种问题,有人会说用进程锁,那是不行的,如果把xx.py分别启动两次,没有共同的父子进程,属于跨解释器的,进程锁是不行的。
nb_log是采用的文件锁,文件锁在linux性能比较好,在win很差劲,导致日志拖累真个代码的性能,所以nb_log是采用把每1秒内的日志
聚合起来,写入一次文件,从而大幅减少了加锁解锁次数,
对比有名的concurrent_log_handler包的ConcurrentRotatingFileHandler,在win上疯狂快速写日志的性能提高了100倍,
在linux上也提高了10倍左右的性能。
"""
只要满足3个条件
1.文件日志
2.文件日志按大小或者时间切割
3.多进程写入同一个log文件,可以是代码内部multiprocess.Process启动测试,
也可以代码内容本身不用多进程但把脚本反复启动运行多个来测试。
把切割大小或者切割时间设置的足够小就很容易频繁必现,平时有的人没发现是由于把日志设置成了1000M切割或者1天切割,
自测时候只随便运行一两下就停了,日志没达到需要切割的临界值,所以不方便观察到切割日志文件的报错。
这里说的是多进程文件日志切割报错即多进程不安全,有的人强奸民意转移话题老说他多线程写日志切割日志很安全,简直是服了。
面试时候把多进程和多线程区别死记硬背 背的一套一套很溜的,结果实际运用连进程和线程都不分。
"""
from logging.handlers import RotatingFileHandler
import logging
from multiprocessing import Process
from threading import Thread
logger = logging.getLogger('test_raotating_filehandler')
logger.addHandler(RotatingFileHandler(filename='testratationg.log', maxBytes=1000 * 100, backupCount=10))
def f():
while 1:
logger.warning('这个代码会疯狂报错,因为设置了100Kb就切割并且在多进程下写入同一个日志文件' * 20)
if __name__ == '__main__':
for _ in range(10):
Process(target=f).start() # 反复强调的是 文件日志切割并且多进程写入同一个文件,会疯狂报错
# Thread(target=f).start() # 多线程没事,所有日志handler无需考虑多线程是否安全,说的是多进程文件日志切割不安全,你老说多线程干嘛?